Smart Model Elimination Machine Learning with Potential Medical Application
Submitted to NHSJS
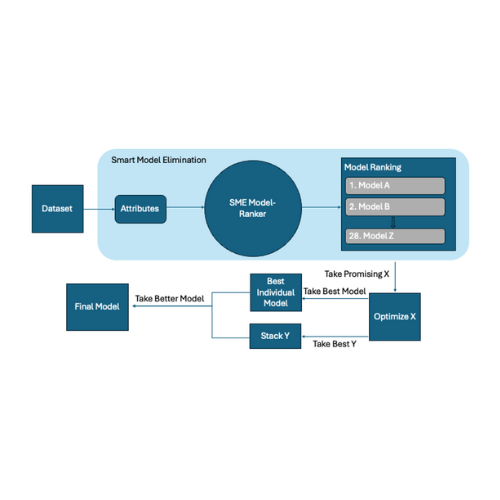
While existing AutoML systems typically run every model in its pool to determine the best model, we propose a new method that eliminates models that are unlikely to be the best model based upon their data features. We show that this is more efficient than brute force methods.
Authors
Eric Su Zhang
ericspring08@gmail.com
St. Mark's School of Texas
Benjamin Joseph Micheal Standefer
bjmstandefer@gmail.com
St. Mark's School of Texas
Stewart Mayer
MayerS@smtexas.org
St. Mark's School of Texas
Links